1. What is RAG ?
Retrieval Augmented Generation (RAG), is a method where you have a foundation model, and you have a library of personal documents – this can be unstructured data in any format. Now your goal is for answering some questions from your persona library of docs, with the help of LLM. Enter RAG – instead of fine-tuning the foundation LLM which is cost and time-consuming, you instead create embeddings from your personal suite of documents, and store it in some database (vector DB or traditional DB that allows storing embedding vectors), and while prompting the LLM, you give all context necessary from this vector database containing information from your documents. It’s like an open-book test, the LLM has its foundation knowledge, you give additional context with your necessary information, now can this LLM + Personal Document Library stored in a DB help answer your questions. This set up is called RAG.
Let’s take an example:
Imagine you have a smart assistant that knows a lot, like a teacher, but isn’t familiar with your specific class notes or the personal projects you’ve worked on. You want this assistant to help you answer questions about your own materials—things it’s never actually seen or studied before.
This is where Retrieval-Augmented Generation (RAG) comes in. Instead of training the assistant on your notes from scratch (which would take tons of time and resources), you can let it access your notes whenever needed, like an “open-book” exam. Here’s how it works:
- Set up Your Library of Knowledge: First, you collect all the documents or files you want this assistant to use—emails, research papers, reports, even unstructured notes. Think of it like building a personal library.
- Make Your Notes Searchable: Next, you “tag” these documents so they’re easily searchable. In technical terms, this means turning each document into an “embedding” (a fancy way of making sure each document can be quickly matched to a relevant question). You then store these embeddings in a searchable database.
- Let the Assistant Look Up Answers: When you ask the assistant a question, it doesn’t just guess based on its general knowledge. Instead, it first “looks up” your documents, finds the most relevant information from your library, and combines it with its own knowledge to give you a much more accurate, context-rich answer.
Here’s a real-life analogy:
Imagine you’re preparing for an interview and have tons of notes and specific information about the company. Instead of memorizing every detail, you organize these notes so that, when asked a question, you can quickly find the exact information you need. Your brain is like the foundational knowledge, and your notes are like your personal library. By combining these, you can give well-informed answers without having to remember everything verbatim.
RAG works similarly: it leverages a pre-trained model’s general knowledge, like your brain’s foundational knowledge, but “looks up” relevant personal information whenever it needs it. This approach gives you the best of both worlds: you save the time and expense of training the assistant on your whole library while still getting responses tailored to your unique knowledge base.
2. Core Components of a RAG System: A Breakdown
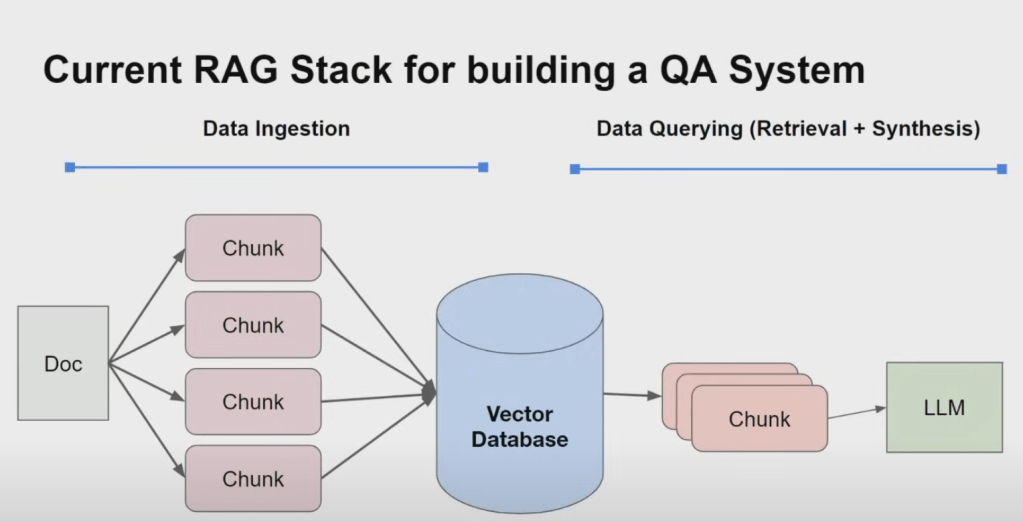
1. Data Ingestion: Preparing Information for Access
The first crucial stage in any RAG pipeline is data ingestion. This involves:
- Gathering data from various sources: RAG systems can work with a diverse range of data sources, including unstructured text documents, SQL databases, knowledge graphs, and more.
- Preprocessing the data: This may involve tasks like cleaning the text, removing irrelevant information, and structuring the data into a format suitable for the RAG system.
- Chunking the data: Large documents are typically divided into smaller chunks, making them more manageable for indexing and retrieval. The choice of chunk size can significantly impact performance, as discussed in our previous conversation about table stakes techniques.
2. Data Querying: Retrieval and Synthesis
The heart of a RAG system lies in its ability to effectively retrieve relevant information and then use that information to generate a coherent and informative response. This data querying process can be further broken down into two main components:
- Retrieval: This stage focuses on identifying the most relevant chunks of information from the ingested data that correspond to a user’s query. The sources highlight several approaches to retrieval, including:
- Semantic Search Using Vector Databases: Text chunks are embedded into a vector space using embedding models. When a user poses a query, it’s also embedded into the same vector space, and the system retrieves the chunks closest to the query in that space. The sources mention vector databases like Chroma and Pinecone as tools for managing these embeddings.
- Metadata Filtering: Structured metadata associated with text chunks can be used to refine retrieval. This allows for combining semantic search with structured queries, leading to more precise results.
- Hybrid Search: Combining different retrieval methods, such as keyword-based search and semantic search, can further enhance retrieval effectiveness.
- Advanced Retrieval Methods: The sources discuss more sophisticated techniques like small-to-big retrieval and embedding references, which aim to improve retrieval precision and overcome limitations of traditional methods.
- Synthesis: Once the relevant information has been retrieved, it’s passed to a large language model (LLM) for response generation. The LLM uses the retrieved context to:
- Understand the user’s query: The LLM processes the query and the retrieved information to grasp the user’s intent and the context of the question.
- Synthesize a coherent response: The LLM generates a response that answers the user’s query, drawing upon the provided context and its own knowledge.
Going Beyond the Basics: Agents and Fine-Tuning
Building production-ready RAG applications often requires going beyond these fundamental components. Agentic methods can be incorporated to enhance the reasoning and decision-making capabilities of RAG systems, allowing them to tackle more complex tasks and queries.
Additionally, fine-tuning techniques can be applied to various stages of the RAG pipeline to further improve performance. This could involve:
- Fine-tuning embedding models: Optimizing embeddings to better represent the specific data and tasks relevant to the application.
- Fine-tuning LLMs: Training the LLM on synthetic datasets to enhance its ability to synthesize responses, reason over retrieved information, and generate structured outputs.
By carefully considering and implementing these additional strategies, developers can create RAG systems that are more robust, accurate, and capable of handling a wider range of real-world applications.
3. Challenges in Building Production-Ready RAG Systems
Response Quality Challenges
- Retrieval Issues: The sources point to poor retrieval as a significant challenge. If the retrieval stage doesn’t return relevant chunks from the vector database, the LLM won’t have the right context for generating accurate responses. Issues include:
- Low Precision: Not all retrieved chunks are relevant, leading to hallucinations and “loss in the middle” problems, where crucial information in the middle of the context window gets overlooked by the LLM.
- Low Recall: The retrieved set of information might not contain all the necessary information to answer the question, possibly due to insufficient top-K values.
- Outdated Information: The retrieved information might be out of date, leading to inaccurate responses.
- LLM Limitations: The sources acknowledge limitations inherent to LLMs, which contribute to response quality challenges. These include:
- Hallucination: The LLM might generate inaccurate information not supported by the retrieved context.
- Irrelevance: The LLM’s response might not directly address the user’s query.
- Toxicity and Bias: The LLM might generate responses that are harmful or biased, reflecting biases present in the training data.
RAG Pipeline Challenges
Beyond response quality, the sources identify various challenges throughout the RAG pipeline:
- Data Ingestion and Optimization:
- Beyond Raw Text: The sources suggest exploring storage of additional information beyond raw text chunks in the vector database to enhance context and retrieval.
- Chunk Size Optimization: Experimenting with chunk sizes is crucial, as it significantly impacts retrieval and synthesis performance. Simply increasing the number of retrieved tokens doesn’t always improve performance.
- Embedding Representations: Pre-trained embedding models might not be optimal for specific tasks or datasets. The sources propose optimizing embedding representations for improved retrieval performance.
- Retrieval Algorithms: Relying solely on retrieving the top-K most similar elements from the vector database often proves insufficient. The sources recommend exploring more advanced retrieval techniques.
- Limited Reasoning Capabilities: The sources highlight the limitation of basic RAG systems in handling complex tasks requiring multi-step reasoning or advanced analysis, as they primarily rely on the LLM for synthesis at the end of the retrieval process.
- Fine-tuning Requirements: The sources emphasize the need to fine-tune various components of the RAG pipeline for optimal performance, including:
- Embedding Fine-tuning: Fine-tuning embeddings on a synthetic dataset generated from the data corpus can improve retrieval accuracy. This can be achieved by fine-tuning either the base model or an adapter on top of it.
- LLM Fine-tuning: Fine-tuning smaller LLMs using a synthetic dataset generated by a larger, more capable LLM can enhance response quality, reasoning ability, and structured output generation.
A task-specific approach and robust performance evaluation to good identify bottlenecks and prioritize improvement strategies across the RAG pipeline.
What are some table stakes methods for improving RAG performance ?
Refer to this page @ ProductBulb to continue reading !!
Reference: https://youtu.be/TRjq7t2Ms5I?list=TLGGrRQYbcv1NwwzMDEwMjAyNA
